Golang 定时器底层实现深度剖析
本文将基于 Golang 源码对 Timer 的底层实现进行深度剖析。主要包含以下内容:
- Timer 和 Ticker 在 Golang 中的底层实现细节,包括数据结构等选型。
- 分析
time.Sleep的实现细节,Golang 如何实现 Goroutine 的休眠。
注:本文基于 go-1.13 源码进行分析,而在 go 的 1.14 版本中,关于定时器的实现略有一些改变,以后会再专门写一篇文章进行分析。
概述
我们在日常开发中会经常用到 time.NewTicker 或者 time.NewTimer 进行定时或者延时的处理逻辑。
Timer 和 Ticker 在底层的实现基本一致,本文将主要基于 Timer 进行探讨研究。Timer 的使用方法如下:
import (
"fmt"
"time"
)
func main() {
timer := time.NewTimer(2 * time.Seconds)
<-timer.C
fmt.Println("Timer fired")
}在上面的例子中,我们首先利用 time.NewTimer 构造了一个 2 秒的定时器,同时使用 <-timer.C 阻塞等待定时器的触发。
Timer 的底层实现
对于 time.NewTimer 函数,我们可以轻易地在 go 源码中找到它的实现,其代码位置在 time/sleep.go#L82。如下:
time/sleep.gofunc NewTimer(d Duration) *Timer { c := make(chan Time, 1) t := &Timer{ C: c, r: runtimeTimer{ when: when(d), f: sendTime, arg: c, }, } startTimer(&t.r) return t }
NewTimer 主要包含两步:
- 创建一个 Timer 对象,主要包括其中的
C属性和r属性。r属性是runtimeTimer类型。 - 调用
startTimer函数,启动 timer。
在 Timer 结构体中的属性 C 不难理解,从最开始的例子就可以看到,它是一个用来接收 Timer 触发消息的 channel。注意,这个 channel 是一个有缓冲 channel,缓冲区大小为 1。
我们主要看的是 runtimeTimer 这个结构体:
when: when 代表 timer 触发的绝对时间。计算方式就是当前时间加上延时时间。f: f 则是 timer 触发时,调用的 callback。而arg就是传给 f 的参数。在 Ticker 和 Timer 中,f 都是 sendTime。
timer 对象构造好后,接下来就调用了 startTimer 函数,从名字来看,就是启动 timer。具体里面做了哪些事情呢?
startTimer 具体的函数定义在 runtime/time.go 中,里面实际上直接调用了另外一个函数 addTimer。我们可以看下 addTimer 的代码 /runtime/time.go#L131:
func addtimer(t *timer) {
// 得到要被插入的 bucket
tb := t.assignBucket()
// 加锁,将 timer 插入到 bucket 中
lock(&tb.lock)
ok := tb.addtimerLocked(t)
unlock(&tb.lock)
if !ok {
badTimer()
}
}可以看到 addTimer 至少做了两件事:
- 调用
assignBucket,得到获取可以被插入的 timersBucket - 调用
addtimerLocked将 timer 插入到 timersBucket 中。从函数名可以看出,这同时也是个加锁操作。
那么问题来了,timersBucket 是什么?timer 插入到 timersBucket 中后,会以何种方式触发?
timersBucket
在 go 1.13 的 runtime 中,共有 64 个全局的 timersBucket。每个 timersBucket 负责管理一些 timer。
timer 的整个生命周期包括创建、销毁、唤醒和睡眠等都由 timersBucket 管理和调度。
timersBucket 的结构: 最小四叉堆
每个 timersBucket 实际上内部是使用最小四叉堆来管理和存储各个 timer。
最小堆是非常常见的用来管理 timer 的数据结构。在最小堆中,作为排序依据的 key 是 timer 的 when 属性,也就是何时触发。即最近一次触发的 timer 将会处于堆顶。如下图:
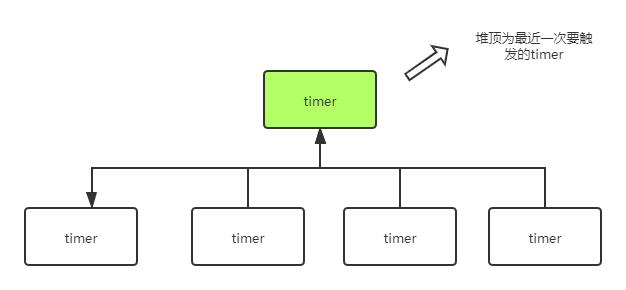
关于四叉堆的具体实现,这里没有什么特殊需要介绍的,与二叉树基本一致。有兴趣的同学可以直接参考二叉树相关实现即可。
timerproc 的调度
每个 timersBucket 负责管理一堆这样有序的 timer,同时每个 timersBucket 都有一个对应的名为 timerproc 的 goroutine 来负责不断调度这些 timer。代码在 /runtime/time.go#L247
对于每个 timersBucket 对应的 timeproc,该 goroutine 也不是时时刻刻都在监听。timerproc 的主要流程概括起来如下:
- 创建。 timeproc 是懒加载的,虽然 64 个 timersBucket 一直是存在的,但是这些 timerproc 对应的 goroutine 并不是一开始就存在。第一个 timer 被加到 timersBucket 中时,才会调用
go timerproc(tb), 创建该 goroutine。 - 调度。从 timersBucket 不断取堆顶元素,如果堆顶的 timer 已触发,则将其从最小堆中移除,并调用对应的 callback。这里的 callback 也就是
runtimeTimer结构体中的f属性。 - 如果 timer 是个 ticker(周期性 timer),则生成新的 timer 塞进 timersBucket 中。
- 挂起。如果 timersBucket 为空,意味着所有的 timer 都被消费完了。则调用
gopark挂起该 goroutine。 - 唤醒。当有新的 timer 被添加到该 timersBucket 中时,如果 goroutine 处于挂起状态,会调用 goready 重新唤醒 timerproc。
当 timer 触发时,timerproc 会调用对应的 callback。对于 timer 和 ticker 来说,其 callback 都是 sendTime 函数,如下:
func sendTime(c interface{}, seq uintptr) {
select {
case c.(chan Time) <- Now():
default:
}
}这里的 c interface{},也就是我们上文中提到的,在定义 timer 或 ticker 时,timer 对象中的 C 属性, 在 timer 和 ticker 中,它都被初始化为长度为 1 的有缓冲 channel。
调用 sendTime 时,会向 channel 中传递一个值。由于是缓冲为 1 的 buffer,因此当缓冲为空时,sendTime 可以无阻塞地把数据放到 channel 中。
如果定时时间过短,也不用担心用户调用 <-timer.C 接收不到触发事件,因为事件已经放到了 channel 中。
而对于 ticker 来说,sendTime 会被调用多次,而 channel 的缓冲长度只有 1。如果 ticker 没有来得及消费 channel,会不会导致 timerproc 调用 callback 阻塞呢?
答案是不会的。因为我们可以看到,在这个 select 语句中,有一个 default 选项,如果 channel 不可写,会触发 default。
对于 ticker 来说,如果之前的触发事件没有来得及消费,那新的触发事件到来,就会被立即丢弃。
因此对于 timerproc 来说,调用 sendTime 的时候,永远不会阻塞。这样整个 timerproc 的过程也不会因为用户侧的行为,导致某个 timer 没有来得及消费而造成阻塞。
为什么是 64 个 timerBucket?
64 个 timersBucket 的定义代码如下,在 /runtime/time.go#L39 可以看到。
/runtime/time.goconst timersLen = 64 var timers [timersLen]struct { timersBucket // The padding should eliminate false sharing // between timersBucket values. pad [cpu.CacheLinePadSize - unsafe.Sizeof(timersBucket{})%cpu.CacheLinePadSize]byte }
不过为什么是 64 个 timersBucket,而不是一个,或者为什么不干脆与 GOMAXPROCS 的大小保持一致呢?
首先,在 go 1.10 之前,go runtime 中的确只有一个 timers 对象,负责管理所有 timer。这个时候也就没有分桶了,整个定时器调度模型非常简单。但问题也非常的明显:
- 创建和停止 timer 都需要对 timersBucket 进行加锁操作。
- 当 timer 过多时,单个 timersBucket 的调度负担太重,可能会造成 timer 的延迟。
因此,在 go 1.10 中,引入了全局 64 个 timer 分桶的策略。将 timer 打散到分桶内,每个桶负责自己分配到的 timer 即可。好处也非常明显,可以有效降低了锁粒度和 timer 调度的负担。
至于为什么是 64 个 timersBucket,这点在源码注释中也有详细的说明:
Ideally, this would be set to GOMAXPROCS, but that would require dynamic reallocation.
The current value is a compromise between memory usage and performance that should cover the majority of GOMAXPROCS values used in the wild.
理想情况下,分桶的个数和保持 GOMAXPROCS 一致是最优解。但是这就会涉及到 go 启动时的动态内存分配。作为语言的runtime应该尽量减少程序负担,而 64 个 timersBucket 则是内存占用和性能之间的权衡结果了。
每个 timersBucket 具体负责管理的 timer 和 go 调度模型 GMP 中 P 有关,代码如下:
func (t *timer) assignBucket() *timersBucket {
id := uint8(getg().m.p.ptr().id) % timersLen
t.tb = &timers[id].timersBucket
return t.tb
}可以看到,timer 获取其对应的 timersBucket 时,是根据 golang 的 GMP 调度模型中的 P 的 id 进行取模。而当 GOMAXPROCS > 64, 一个 timersBucket 将会同时负责管理多个 P 上的 timer。
为什么是四叉堆
timersBucket 里面使用最小堆管理 Timer,但与我们常见的使用二叉树来实现最小堆不同,Golang 这里采用了四叉堆 (4-heap) 来实现。这里 Golang 并没有直接给出解释。
这里直接贴一段 知乎网友对二叉堆和 N 叉堆的分析。
- 上推节点的操作更快。假如最下层某个节点的值被修改为最小,同样上推到堆顶的操作,N 叉堆需要的比较次数只有二叉堆的 倍。
- 对缓存更友好。二叉堆对数组的访问范围更大,更加随机,而 N 叉堆则更集中于数组的前部,这就对缓存更加友好,有利于提高性能。
C 语言知名开源网络库 libev,其timer定时器实现可以在编译时选择采用四叉堆还是二叉堆。在它的注释里提到四叉堆相比来说缓存更加友好。 根据benchmark,在 50000 + 个 timer 的场景下,四叉堆会有 5% 的性能优势。具体可见 libev/ev.c#L2227
sleep 的实现
我们通常使用 time.Sleep(1 * time.Second) 来将 goroutine 暂时休眠一段时间。sleep 操作在底层实现也是基于 timer 实现的。代码在 runtime/time.go#L84。有一些比较有意思的地方,单独拿出来讲下。
我们固然也可以这么做来实现 goroutine 的休眠:
timer := time.NewTimer(2 * time.Seconds)
<-timer.C这么做当然可以。但 golang 底层显然不是这么做的,因为这样有两个明显的额外性能损耗。
- 每次调用 sleep 的时候,都要创建一个 timer 对象。
- 需要一个 channel 来传递事件。
既然都可以放在 runtime 里面做。golang 里面做的更加干净:
- 每个 goroutine 底层的
G对象上,都有一个 timer 属性,这是个 runtimeTimer 对象,专门给 sleep 使用。当第一次调用 sleep 的时候,会创建这个 runtimeTimer,之后 sleep 的时候会一直复用这个 timer 对象。 - 调用 sleep 时候,触发 timer 后,直接调用 gopark,将当前 goroutine 挂起。
- timerproc 调用 callback 的时候,不是像 timer 和 ticker 那样使用
sendTime函数,而是直接调goready唤醒被挂起的 goroutine。
这个做法和libco的poll实现几乎一样:sleep时切走协程,时间到了就唤醒协程。
总结
分析 timer 的实现,可以明显的看到整个设计的演进,从最开始的全局 timers 对象,到分桶 bucket,以及到 go1.14 最新的 timer 调度。整个过程也可以学习到整个决策的走向和取舍。