剖析Golang Bigcache的极致性能优化
Bigcache是用Golang实现的本地内存缓存的开源库,主打的就是可缓存数据量大,查询速度快。 在其官方的介绍文章《Writing a very fast cache service with millions of entries in Go》一文中,明确提出了bigcache的设计目标:
- 多: 缓存的元素数量非常大,可以达到百万级或千万级。
- 快: 对延迟有非常高的要求,平均延迟要求在5毫秒以内。redis、memcached之类的就不考虑在内了,毕竟用Redis还要多走一遍网络IO。
- 稳: 99.9分位延迟应在10毫秒左右,99.999分位延迟应在400毫秒左右。
目前有许多开源的cache库,大部分都是基于map实现的,例如go-cache,ttl-cache等。bigcache明确指出,当数据量巨大时,直接基于map实现的cache库将出现严重的性能问题,这也是他们设计了一个全新的cache库的原因。
本文将通过分析bigcache v3.1.0的源码,揭秘bigcache如何解决现有map库的性能缺陷,以极致的性能优化,实现超高性能的缓存库。
bigcache的设计思想
如何避免GC对map的影响
当map里面数据量非常大时,会出现性能瓶颈。这是因为在Golang进行GC时,会扫描map中的每个元素。当map足够大时,GC时间过长,会对程序的性能造成巨大影响。
根据bigcache介绍文章的测试,在缓存数据达到数百万条时,接口的99th百分位延迟超过了一秒。监测指标显示堆中超过4,000万个对象,GC的标记和扫描阶段耗时超过了四秒。这样的延迟对于bigcache来说是完全无法接受的。
这个问题在Go 1.5版本中有一项专门的优化(issue-9477):如果map的key和value中使用没有指针,那么GC时将无需遍历map。例如map[int]int、map[int]bool。这是当时的pull request: go-review.googlesource.com/c/go/+/3288。里面提到:
Currently scanning of a map[int]int with 2e8 entries (~8GB heap)
takes ~8 seconds. With this change scanning takes negligible time.
对2e8个元素的map[int]int上进行了测试,GC扫描时间从8秒减少到0。
为什么当map的key和value不包含指针时,可以省去对元素的遍历扫描呢?这是因为map中的int、bool这种不可能会和外部变量有引用关系:
- int、bool这种在map中存储的就是值本身。
- map的key和value不可被寻址。也就是说,以
map[int]int为例,外部没有办法取到这个key和value的指针,那也就无从引用了。
这个优化听起来非常强大好用,但是在Golang中指针无处不见,结构体指针、切片甚至字符串的底层实现都包含指针。一旦在map中使用它们(例如map[int][]byte、map[string]int),同样会触发垃圾回收器的遍历扫描。
bigcache的整体设计
bigcache整体设计的出发点都是基于上文提到的Golang对Map GC优化,整个设计思路包含几个方面:
- 数据分片存储,以降低锁冲突并提升并发量。
- 避免在map中存储指针,从而避免在GC时对map进行遍历扫描。
- 采用FIFO式的Ring Buffer设计,简化整体内存设计逻辑。
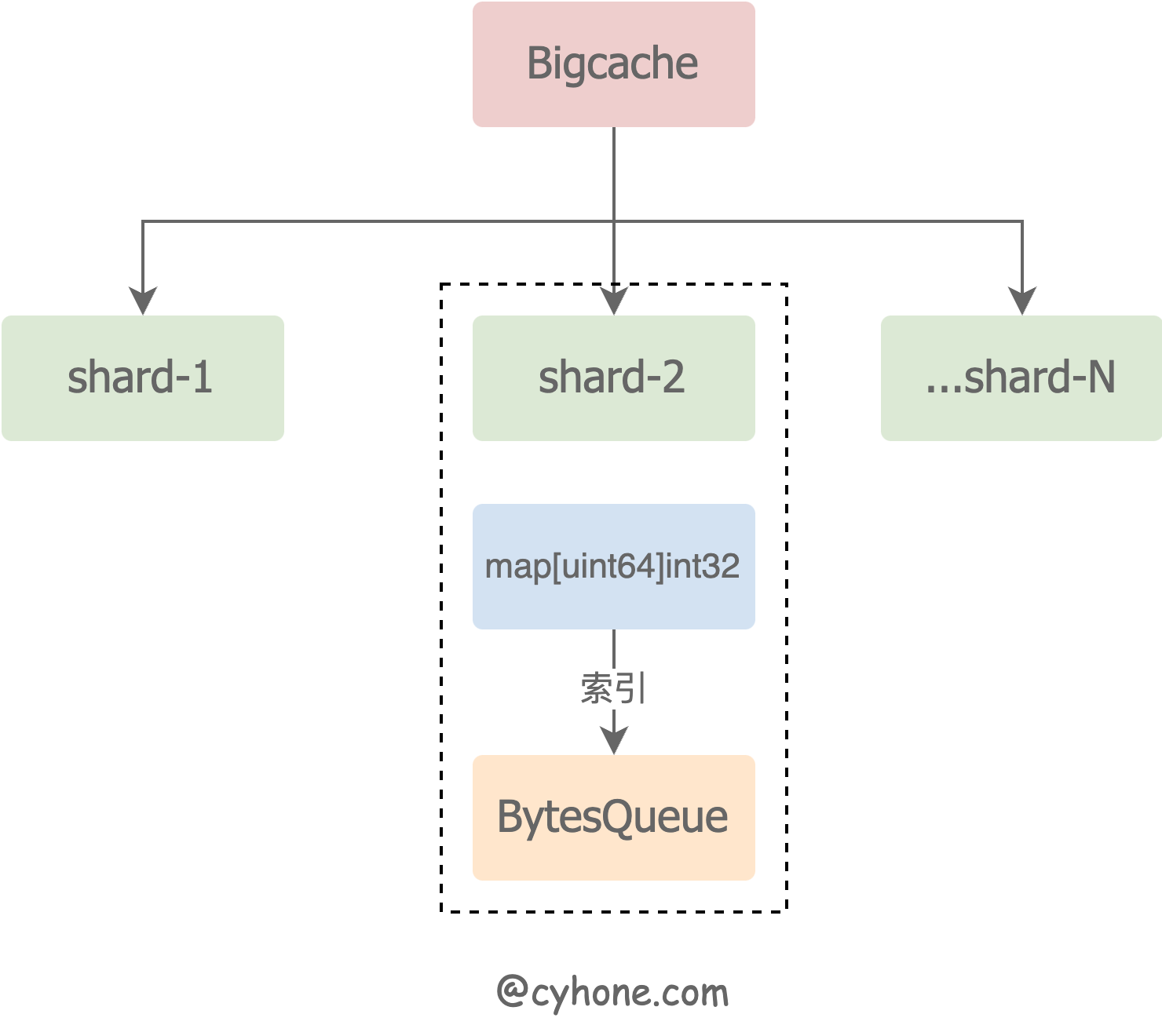
数据分shard
这是一个非常常见的数据存储优化手段。表面上bigcache中所有的数据是存在一个大cache里面,但实际上底层数据分成了N个不互重合的部分,每一个部分称为一个shard。
在Set或者Get数据时,先对key计算hash值,根据hash值取余得到目标shard,之后所有的读写操作都是在各自的shard上进行。
以Set方法为例:
1 | func (c *BigCache) Set(key string, entry []byte) error { |
这么做的优势是可以减少锁冲突,提升并发量:当一个shard被加上Lock的时候,其他shard的读写不受影响。
在bigcache的设计中,对于shard有如下要求:
- 一旦建好,shard将不改变。这带来的两点好处:
- 不用再考虑shard变化时的数据迁移问题。
- 因为shard数组是固定不变的,因此从shard数组中根据hash值取目标shard的时候,就无需加锁了。
- shard个数必须是2的平方数。这么做的好处是,对2的平方数取余可以改成位运算,会比传统的
%快很多(根据不权威的benchmark,计算速度大概会有2倍左右的差距)。
1 | func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) { |
- bigcache的shard数默认值是1024。
map不存原始数据,避免GC遍历扫描
前文提到,map的key和value一旦涉及指针相关的类型,GC时就会触发遍历扫描。
因此在bigcache的设计中,shard中的map直接定义为了map[uint64]uint32 ,避免了存储任何指针。shard的结构体定义如下:
1 | type cacheShard struct { |
其中:hashmap的key是cache key的hash值,而value仅仅是个uint32。这显然不是我们Set的时候value的原始byte数组。
那value的原始值存在了哪里?答案是cacheShard中的另外一个属性entries queue.BytesQueue。
queue.BytesQueue是一个ring buffer的内存结构,本质上就是个超大的[]byte数组,里面存放了所有的原始数据。每个原始数据就存放在这个大[]byte数组中的其中一段。
hashmap中uint32的value值存放的就是value的原始值在BytesQueue中的数组下标。(其实并不只是原始的value值,里面也包含了key、插入时间戳等信息)
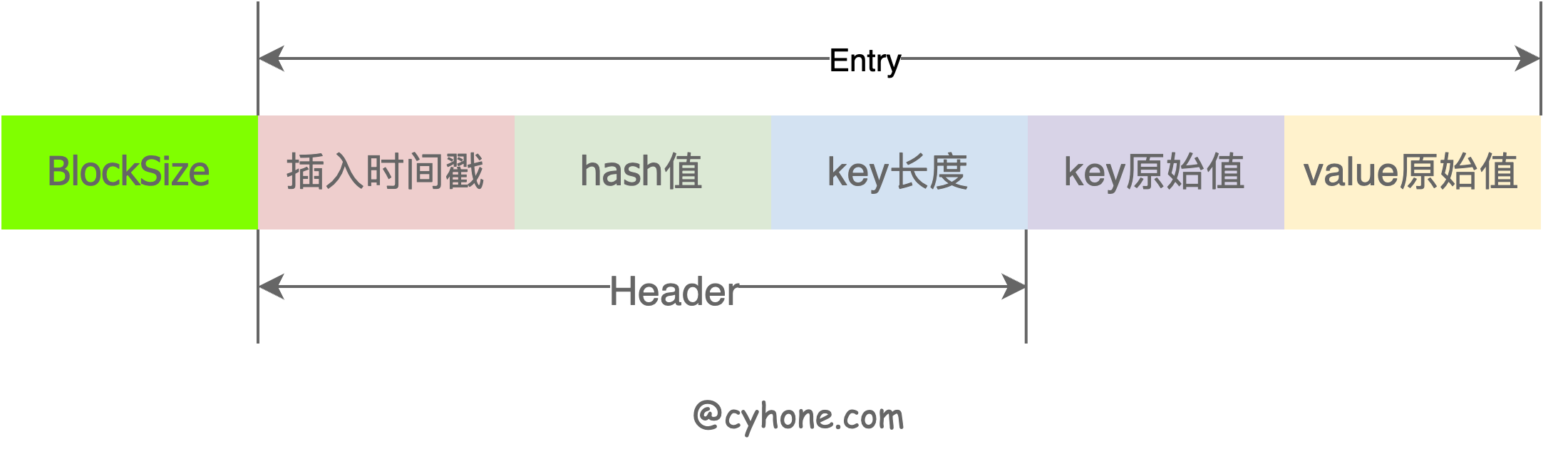
之所以用一个大的[]byte数组和ring buffer结构,除了方便管理和复用内存之外,一个更重要的原因是:对于[]byte数组, GC时只用看做一个变量扫描,无需再遍历全部数组。这样又避免了海量数据对GC造成的负担。
FIFO式的内存结构设计
bigcache在内存结构设计上完全遵循FIFO原则:
- 新增数据,包括对老数据的修改,都是直接Append新数据到
BytesQueue中。基本不直接对内存进行修改和删除等。 - 每个数据项不可以定制单独的缓存时长,必须全部保持一致。这对数据淘汰非常友好,下文会详细讲述。
这样一整套设计约定下来,bigcache的逻辑变成非常简洁明了,但这样同时造成了bigcache的局限性。
Set过程
1 | cache.Set("my-unique-key", []byte("value")) |
前面讲述了bigcache的设计思想之后,Set的整个逻辑也就很清晰了:
- 计算key的hash值,得到对应的shard
- 将key和value等信息序列化成指定格式的[]byte, push到BytesQueue中。
- 根据BytesQueue返回的内存偏移量(也就是数组下标),将key(hash值)和value(数组下标)设置hashmap中。
这里需要注意的是,在bigcache的设计里面,Set时value一定得是个[]byte类型。
前文讲到,bigcache中所有的原始数据都会被塞到一个大的[]byte数组里。因此对于bigcache来说最理想的肯定是直接给到[]byte最为方便,否则还需要考虑序列化等问题。
BytesQueue是一个ring buffer设计,本文不再细究其实现了,和其他ring buffer的结构大同小异。
除了正常的set逻辑外,还有一些额外的情况需要考虑在内:
情况1:如果key之前设置过,Set的时候会如何处理?
在其他cache库的实现中,这种情况一般是找到旧值、删除,然后把新值设置到旧值的位置。
但在bigcache中并不是这样,前文提到,bigcache的内存结构设计是FIFO式的,哪怕是有旧值的情况下,新值也不会复用其内存,依旧是push新的value到队列中。
那旧值将如何处理的呢?我们看下代码:
1 | if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 { |
最核心的一句就是:delete(s.hashmap, hashedKey)
简单来说:之前的旧值并未从内存中移除,仅仅只是将其偏移量从s.hashmap中移除了,使得外部读不到。
那旧值什么时候会被淘汰呢?会有两种情况:
- 如果设置了
CleanWindow,且旧值刚好过时,会被清理的定时器自动淘汰 - 如果设置了
MaxEntrySize或者HardMaxCacheSize,当内存满时,也会触发最旧数据的淘汰。
在此之前,旧值的数据一直都会保留在内存中。
另外还有resetHashFromEntry ,这个逻辑主要是把entry中的hash部分的数值置为0。这么做只是打上一个已处理的标记,保证数据在淘汰的时候不再去调用OnRemove的callback而已。
其实这里还有个场景:当s.hashmap[hashedKey]存在value时,并不一定是设置过这个key,也有可能发生了hash碰撞。
按照上述逻辑,bigcache并未对hash碰撞做特殊处理,统一都把之前相同hash的旧key删除。 毕竟这只是缓存的场景,并不保证之前Set进去的数据一直会存在。
问题2:当ring buffer满时,无法继续push数据,bigcache会如何处理?
情况分成两种:
- 如果
entries queue.BytesQueue未达到设定的HardMaxCacheSize(最大内存上限),或者无HardMaxCacheSize要求,则直接扩容queue.BytesQueue直到达到上限。不过扩容的时候,是创建了一个新的空[]byte数组,把原有数据copy过去。 - 如果内存已达上限,无法继续扩容,则会尝试删除最旧数据(无论是否过期),直至可以将数据放到
BytesQueue中。如果这个时候新数据非常大,可能会为此淘汰掉许多旧数据。
Get和GetWithInfo
1 | entry, _ := cache.Get("my-unique-key") |
Get基本上是Set的逆过程,整个过程更简单一些,没有太多额外的知识可讲。不过在使用时,需要注意的是:
- Get时如果数据到达了过期时间,但暂时还没有被清掉,这个时候也能正常查到value,不会报错。 其实这个倒是符合大多数的实际需求场景,实际场景中其实对缓存过期时间并没有那么敏感,短时间读到旧值一般都是可以接受的。
- 如果对于缓存时间敏感的场景,可以使用GetWithInfo接口,返回值中有是否过期的标识。
删除
跟删除有关的核心逻辑只有这两行,整个逻辑和Set过程中清除旧值的一样:
1 | ... |
不过在调用bigcache.Delete接口时需要注意的是,如果key不存在时,会返回一个ErrEntryNotFound
过期淘汰
上面讲到删除逻辑和set时清除旧值时,都只是简单的把key从map中删除,不让外部读取到而已。那原始值什么时候删呢?答案就是过期淘汰。
bigcache有个设计上的优势:bigcache没有开放单个元素的可过期时间,所有元素的cache时长都是一样的,这就意味着所有元素的过期时间在队列中天然有序。
这就使得淘汰逻辑非常简单,代码如下:
1 | func (s *cacheShard) cleanUp(currentTimestamp uint64) { |
其实就是从头到尾遍历数组,直至元素不过期就跳出。
另外,即使淘汰过期数据时,数据也并未被真实的删除,仅仅对应于ring buffer中head和tail下标的移动。
这样整个删除过程非常轻量级,好处不仅在于逻辑更简单,更重要的是,淘汰时需要对整个shard加写锁,这种对有序数组的遍历删除,加锁的时间会非常短(当然也取决于这个时刻过期的数据条数)。
当然,这也意味着bigcache的局限性:数据过期模式非常简单,这种FIFO式的数据淘汰相比于LRU、LFU来说,缓存命中率会低不少。
此外从这里可以得知,哪怕是经过了淘汰,bigcache的内存也不会主动降下去,除非外部调用了Reset方法。因此在实际实践中,我们最好是控制好HardMaxCacheSize,以免OOM。
细节的极致优化
bigcache的主要逻辑已经基本讲完了,作为一个以性能为卖点的cache库,bigcache在细节上也有大量的性能优化:
-
varint的使用: 在最开始讲bigcache中每个entry结构的设计时,图中有一个blocksize,代表数据entry的大小,用于bigcache确定数据边界。这里blocksize用到了varint来表示,可以一定程度上减小数据量。具体varint的介绍可以参考我的另外一篇文章《解读 Golang 标准库里的 varint 实现》。
-
buffer内存复用:在每次set数据的时候,上面varint和整个entry都需要动态地分配内存,bigcache这里在每个shard中内置了两个全局的buffer:
headerBuffer和entrybuffer,避免了每次的内存分配。 -
自己实现fnv Hash: bigcache自己实现了一套fnv hash,并没有用go官方标准库的,这也是基于性能的考虑。在Go官方的实现中 hash/fnv/fnv.go,创建Fnv对象的时候,有这么一段逻辑:
1
2
3
4func New32a() hash.Hash32 {
var s sum32a = offset32
return &s
}根据Golang的逃逸分析,s这个变量在结束的时候会被外部用到,这样Go编译器会将其分配到堆上(逃逸到堆上)。
我们知道,直接在栈上操作内存比堆上更快速,因此bigcache实现了一个基于栈内存的fnv hash版本。
序列化问题
bigcache的介绍文章中也提到,JSON序列化问题成为了一个性能问题:
While profiling our application, we found that the program spent a huge amount of time on JSON deserialization. Memory profiler also reported that a huge amount of data was processed by
json.Marshal.
他们换成了ffjson来替换go标准库中的json操作,性能得到了不少的提升。
不过这样给我们提了个醒,如果不是海量数据,尚未达到map的gc瓶颈,倒是没有必要直接就上bigcache, 毕竟序列化所带来的开销也不算低。
附录:bigcache配置详解
bigcache.Config中有很多配置参数,这里大概列一下:
1 | // Config for BigCache |